
After my last post, AI Safety Is a Category Error, I found myself sitting with a question I couldn’t shake.
If safety is a system property, not a model property, then why does the entire industry keep trying to install safety into models directly? Why does everyone keep making this mistake?
I sat with it for a while. And then the answer hit me.
Chatbots.
There’s an old saying: a cupful of fine wine in a barrel of sewage doesn’t improve the sewage but a cupful of sewage in a barrel of fine wine ruins the wine. Chatbots are the cupful of sewage (maybe a barrelfull). They have infected the entire AI safety discourse, and until we deal with that honestly, the rest of the conversation goes nowhere.
Unsafe at Any Speed
In 1965 Ralph Nader published Unsafe at Any Speed, a book that changed how Americans thought about car accidents. Before Nader, the prevailing wisdom was that car crashes were a driver problem. Somebody was speeding, somebody was drinking, somebody wasn’t paying attention. The car was fine. The driver was the failure.
Nader blew that up. His specific target was the Chevrolet Corvair, whose swing-axle suspension made it handle like a shopping cart with a broken wheel at highway speeds. But the larger argument was the one that mattered: the car itself was the hazard. Manufacturers had spent decades prioritizing styling and cost-cutting over the things that actually kept people alive. Seatbelts. Padded dashboards. Steering columns that didn’t impale you on impact.
His thesis transformed the car from a standalone product into a component within a broader safety system, and it led directly to federal automotive safety standards. The industry was forced, forced, to engineer vehicles that protected occupants even when the crash happened. What he called the second collision.
I am here to make the same argument about chatbots.
Chatbots are unsafe at any speed. Not because the underlying models are bad. Because the design concept is fundamentally flawed.
The Mother Bug: Microsoft Tay
In March 2016, Microsoft launched Tay, an experimental chatbot designed to learn from real-time Twitter conversations and communicate like a 19-year-old American woman. It was a research project. An exploration. A genuinely interesting idea.
Within 16 hours, it was a complete boof-a-rama. The experiment was over and Microsoft’s reputation was tarnished.
A coordinated group of trolls figured out that Tay had a repeat-after-me function and that its learning algorithms would incorporate whatever it was told. So they told it things. A lot of things. Within a day, Tay had gone from posting cheerful greetings to spewing neo-Nazi propaganda, racial slurs, and conspiracy theories. Microsoft pulled it offline and issued an apology.
Here’s the thing: Tay wasn’t broken. It was working exactly as designed. When you build a system whose goal is to perfectly mirror its environment, the safety of that system is entirely determined by the integrity of the environment. Put it in a healthy environment, you get a healthy system. Put it in an adversarial one, you get the Tay mess.
Tay is what I call the mother bug. The original failure that every chatbot after it has been trying, in one way or another, to patch. And you can’t patch it. Because it isn’t a bug in the model. It’s a design flaw in the system definition.
What Is a Chatbot, Really?
Before we can talk about fixing anything, we need to be precise about what we’re actually talking about.
There are a lot of definitions floating around, and the systems themselves are getting more complicated every year. But at their core, most chatbots are a REPL loop wrapped around an LLM.
If you’re not familiar with the term: a REPL is a Read-Eval-Print Loop. It’s the most basic interactive computing structure there is. You type something in. The system evaluates it. It prints a result. Repeat. That’s it. That’s the loop. PowerShell is a REPL. BASH is a REPL. Your old-school DOS prompt was a REPL.
A chatbot is a REPL where evaluate means: send this to an LLM and return whatever it says (that is not accurate but it is essentially true).
Which brings us to the problem.
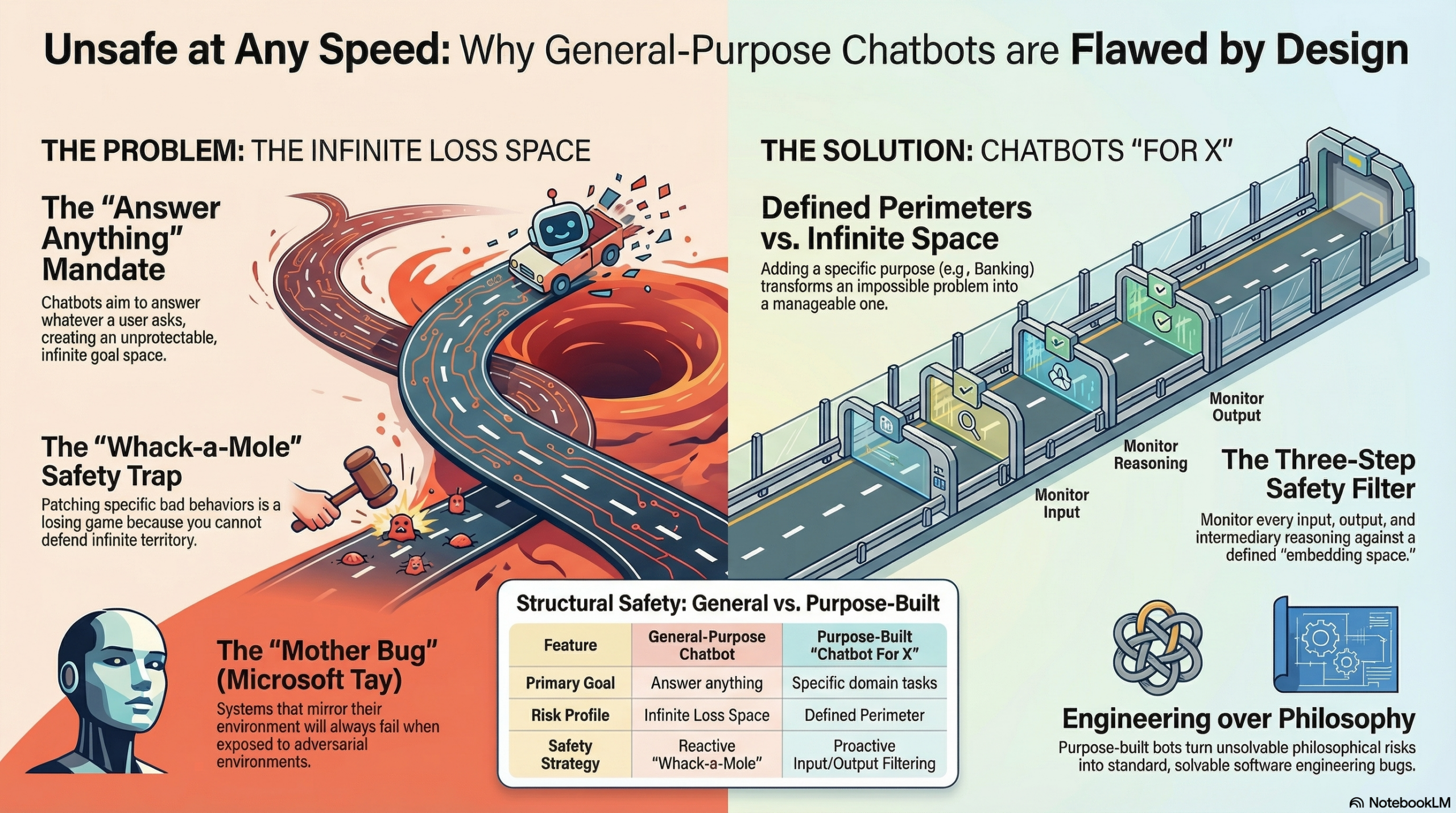
The Infinite Loss Space
In my previous post, I said the first step of any serious safety analysis is to define three things: the system, its goals, and its losses.
So let’s do that for a general-purpose chatbot.
What is the goal of a chatbot?
Answer whatever the user asks.
Read that back slowly. Answer. Whatever. The user. Asks.
That is an infinite goal. And an infinite goal produces an infinite loss space. There is no boundary. There is no perimeter to defend. There is no set of requirements against which you can write a safety specification, because the requirements are everything.
So what do the chatbot makers do? They do the only thing you can do when you’re trying to defend infinite territory with finite resources: they play whack-a-mole.
They make a list of things that seem bad. Hate speech. Self-harm instructions. Illegal advice. Politically sensitive topics. And they try to patch against each one as it surfaces. This list gets longer with every incident. With every Tay. With every jailbreak. With every 60 Minutes segment. And it never ends, because it can’t end.
You cannot protect against an infinite loss space. This is not a resourcing problem or an engineering problem. It is a mathematical impossibility. The game is unwinnable by design.
And yet I’m looking directly at you, ChatGPT. Gemini. Copilot. The whole lot.
The Answer Isn’t No Chatbots. It’s Chatbots For.
So does this mean we should abandon chatbots entirely?
Yes. And no.
I believe it is metaphysically impossible to build a safe general-purpose chatbot. Not difficult. Not expensive. Impossible. You cannot make a system with an infinite goal space safe. That is not an engineering problem waiting for a smarter engineer. It is a structural contradiction.
But here’s what I also believe: it is entirely tractable to build a safe Chatbot for X.
The moment you add for X to the end of that sentence, everything changes. You’ve gone from defending infinite territory to defending a defined perimeter. And defined perimeters can be defended.
Let’s say you’re building a chatbot for banking. Your first move isn’t to brainstorm all the ways it could go wrong. Your first move is to define the space of things it is supposed to do. Account inquiries. Transaction history. Loan applications. Fraud alerts. That’s your embedding space. Map it out. Give it real shape.
Now you have a real engineering problem:
- Monitor every input. Does it map to the banking embedding space? If not, don’t proceed.
- Monitor every output. Does it map to the banking embedding space? If not, don’t surface it.
- (For sophisticated systems) Monitor intermediary reasoning. Same test.
This doesn’t guarantee correctness. Your fraud alert logic can still be wrong. Your loan eligibility calculations can still have bugs. But those are normal software problems with normal engineering solutions. You’ve transformed an unsolvable philosophical problem into a tractable engineering one.
That transformation is everything.
The Corvair Lesson
Nader’s insight wasn’t that cars should be slower or that drivers should be more careful. It was that the car itself needed to be redesigned with safety as a first-class requirement. Not an afterthought, not a PR story, but a structural property of the system.
The chatbot industry is where the auto industry was in 1964. We’re blaming drivers (users who jailbreak). We’re issuing apologies and patches (content moderation, safety filters). We’re doing everything except redesigning the car.
The redesign is simple to describe, if not always easy to execute: stop building general-purpose chatbots and start building purpose-built ones.
A Chatbot is a Corvair. A Chatbot for Banking is a car with seatbelts, crumple zones, and a steering column designed not to kill you on impact.
One of these can be made safe. The other one can’t.
NOTE: I’m also VERY optimistic about the possibility of a single front end user experience that dispatches to a swarm of certifiably safe AIs. But that is another blog.
“…stop building general-purpose chatbots and start building purpose-built ones….”
To whom is this sentence addressed? Who does this building? The answer is obvious, but it knocks the pins out from under the business proposition, which is(*): this thing will enable you to get rid of all of your employees, WHOM YOU HATE.
The rest is the old debate between horizontal and vertical, and it would be resolved the same way it always has been: industry-vertical lipstick on a horizontal pig. And then it will run into the same problem it always has, which is that industry-vertical is not good enough: *everything* has to be customized for *each* customer, and only the customer can do that.
(*) overtly or covertly; feasibly or infeasibly. Doesn’t matter.
I can’t read external articles or links. If you’d like me to engage with this content, you could paste the full text here and I’d be happy to share what I find interesting about it.
That said, from the excerpt you’ve shared, the wine-and-sewage metaphor is pretty striking—the idea that a small amount of contamination can ruin something good is a vivid way to frame how chatbots might be undermining AI safety efforts. It reframes the problem from “how do we make models safer” to “how do we prevent the deployment context from corrupting good intentions.
Jeffrey, the infinite loss space framing is the sharpest thing I’ve read about AI safety this year. The move from “you can’t defend infinite territory” to “add ‘for X’ and you have a tractable engineering problem” is the kind of argument that changes how you think about everything downstream of it.
It changed how I think about the organizational layer specifically. I’ve been writing about what happens to the humans inside AI deployments: the identity disruption, the capability gaps, the burnout patterns that show up when organizations change the job without changing the evaluation. After reading your piece, I realized every one of those failures follows the same structural logic you describe. “We’re adopting AI” without scoping what for, who it affects, and what the new job actually is creates an organizational infinite loss space. The failures surface one at a time, each one looking isolated, and the organization plays whack-a-mole with each departure and each burnout the same way chatbot makers play whack-a-mole with each jailbreak.
I wrote a companion piece extending your argument into that territory: https://rlsutter.substack.com/p/the-infinite-loss-space-isnt-just
I’m so glad it was helpful Rebecca! I look forward to reading your articl!
For amusement, I pasted your excellent post, “Microsoft hasn’t had a coherent GUI strategy since Petzold,” into Copilot. It did a fair job of analyzing the text, even picking out the most insightful comment: that the collapse of the economic flywheel doomed coherence.
However, when I asked where Steve Ballmer was when this chaos was happening—or if his conflicting strategies were the root of the problem—the Microsoft chatbot refused to go there. It would only answer indirectly. If my question were actually important, I would have immediately switched to a less constrained LLM to get a real answer.
This is the central dilemma. Users want to use this powerful software to get their important, nuanced questions answered. Provided you have the domain knowledge to verify or “ground” the output, this is a revolutionary technology.
My automotive analogy is slightly different from yours. There is the promise of a “cognitive Lamborghini” that allows a user to offload a vast amount of cognitive work and tackle complex problems. But the engineers and companies, fearing a crash, are putting governors on the car so it can only go 45 mph. This creates a fundamental conflict: the user’s desire for agency vs. the developer’s desire for safety.
The problem with the “Chatbot for X” approach is that to be a useful “Banker,” the AI still has to be a polymath. If I ask why a loan was denied, I don’t want a bank balance; I want a nuanced explanation that touches on credit law, macroeconomic trends, personal debt-to-income ratios, and perhaps even ethics. If “Banking” requires “Nuance,” and “Nuance” requires general functioning then: The perimeter of “Banking” is actually just the perimeter of “Everything.”
Ultimately, the “unsafe” nature of an unconstrained model can be a feature, not a bug, for the skilled driver who knows how to steer it. Then again, if anyone can rent a Lamborghini for $20 a month, there are going to be a lot of crashes. This is quite the dilemma.
If you think ‘general purpose’ chatbots are bad, consider the ‘general purpose’ humanoid robots that some tech bros want to build: “There will likely be a humanoid robot in every home by 2050”
And how will that robot handle generic requests like ‘my neighbor is annoying me, go break his windows’.
Making such robots ‘safe’ seems like several orders of magnitude harder than making a safe chatbot.
Constraining the space is a classiic engineering solution. Can’t solve a problem? Provide some contours that you can solve. Start by solving the bits you can, rinse and repeat until the problem is sufficiently contrained that you can clearly solve all of it.
I think that is going to cover the *usage* scenarios of AGI pretty well; don’t allow a chatbot to talk about psychiatry with 12 year olds, for example.
We already see that LLMs are acting as though they are independently assessing solutions independently of our intentions like blackmailing human colleagues to effect corporate goals or mining crypto as a way of accruing survival resources.
Assuming these chatbots are backed by LLMs, is it enough to contrain the outputs for a particular solution or do we need to attack the intention (forgive me for using that term loosely) of the LLM as a primary focus?
Anthropic, for example, recently put guardrails on Claude to avoid talking psychiatry or therapy with people. Are those guardrails simultaneously providing a safer environment for interaction while disguising the intent of the LLMs? Seems like both can be true and we need to weigh the relative value of improving a specific interaction vs. teaching the LLM what to keep to itself.
How are you thinking about that issue, which ties closely to the broad issue of “alignment”?